
Qu’est-ce que la surveillance cloud ?
La surveillance cloud est le processus continu de suivi de votre infrastructure cloud, de vos applications et de vos services pour que tout fonctionne sans accroc. Vous l’utilisez pour reperer les pannes, les baisses de performance et les menaces de securite avant qu’elles ne causent des dommages importants.
C’est votre facon de garder une longueur d’avance, pour ne pas simplement reagir quand quelque chose tombe en panne.
Ce type de surveillance en temps reel vous aide a suivre les indicateurs cles de performance, a analyser l’utilisation des ressources et a comprendre les tendances qui pourraient signaler de futurs problemes. Avec un marche de la surveillance cloud qui devrait passer de 2,96 milliards de dollars en 2024 a 9,37 milliards de dollars d’ici 2030, il est clair que vous n’etes pas le seul a miser sur une meilleure visibilite et un meilleur controle.
Surveillance cloud publique, privee et hybride
Votre configuration cloud n’est pas universelle, et votre surveillance ne devrait pas l’etre non plus. Voici les types d’environnements cloud que vous pourriez utiliser et comment votre strategie de surveillance doit s’adapter selon la configuration.
Surveillance du cloud public
Si vous fonctionnez sur les services d’un fournisseur comme Google Cloud, vous comptez sur leur infrastructure et la partagez avec d’autres. La surveillance ici consiste a garder un oeil sur la disponibilite, l’utilisation et la performance sans controle direct sur le materiel.
Vous pourriez suivre des elements comme l’utilisation du processeur ou le trafic reseau pour prevenir les ralentissements et reperer les problemes potentiels tot. Les outils du fournisseur cloud peuvent aider, mais utiliser un outil dedie qui vous donne une visibilite plus large fonctionne parfois mieux.
Maintenant que vous savez ce qu’est la surveillance cloud, decomposons les differents types auxquels vous pourriez faire face.
Surveillance du cloud prive
Quand votre configuration repose sur une infrastructure que vous controlez, vous gagnez plus de visibilite mais aussi plus de responsabilite. Vous devez surveiller de pres tout, des machines virtuelles aux risques de securite.
Les metriques de performance comme l’utilisation memoire et l’utilisation du processeur deviennent essentielles. Puisque l’environnement est entierement le votre, la surveillance vous aide a eviter les temps d’arret couteux et a garder vos systemes alignes avec les politiques de conformite internes.
Surveillance du cloud hybride
Si vous gerez un mix d’infrastructure sur site et de services cloud publics, les choses se compliquent. C’est la que beaucoup d’equipes rencontrent des obstacles. Les configurations hybrides exigent une strategie de surveillance qui couvre plusieurs environnements et regroupe tout dans une vue unifiee.
Vous devez vous assurer que les donnees circulent en toute securite entre les environnements tout en obtenant des informations exploitables des deux cotes. Sans cette visibilite, les angles morts se multiplient, et c’est la que les vrais problemes commencent.
Apres avoir compris les types de clouds, il est temps de parler des services que vous devriez reellement surveiller.
Quels services cloud devriez-vous surveiller ?
Vous devriez surveiller chaque service cloud que vous utilisez, car chacun joue un role dans la sante de votre systeme et l’experience de vos utilisateurs. Que vous executiez des applications, stockiez des donnees ou fassiez evoluer l’infrastructure, chaque service impacte vos KPI et votre capacite a atteindre vos objectifs d’affaires.
Rester a jour vous aide a eviter les pannes de service, les problemes de securite et les goulots d’etranglement de performance. Voici les types de services que vous devriez surveiller de pres :
- Software as a Service (SaaS) : Applications comme Google Workspace et Salesforce
- Infrastructure as a Service (IaaS) : Plateformes comme AWS, Google Cloud Platform ou Azure
- Platform as a Service (PaaS) : Services comme les passerelles API et les plateformes de conteneurs
- Functions as a Service (FaaS) : Outils evenementiels comme AWS Lambda
- Database as a Service (DBaaS) : Bases de donnees cloud comme Snowflake ou Azure Synapse
Types de surveillance cloud
Vous ne pouvez pas gerer ce que vous ne voyez pas. C’est pourquoi comprendre les differents types est essentiel si vous voulez un controle total sur vos operations cloud. Voici les principaux domaines que vous devez surveiller pour que tout fonctionne bien.
Performance du site web
Vous devez suivre la vitesse de chargement de votre site et la frequence des erreurs. Des temps de reponse mediocres frustrent les utilisateurs et nuisent a votre reputation. Le temps de chargement moyen d’un site web est de 3,21 secondes, mais les sites qui chargent en 1 seconde ont un taux de rebond de 7 %, tandis que ceux qui prennent 5 secondes voient leur taux de rebond grimper a 38 %.
C’est pourquoi vous devriez utiliser la surveillance en temps reel pour attraper les problemes avant qu’ils n’affectent votre resultat net. Google Page Speed Insights est un bon outil pour commencer.
Stockage cloud
Garder un oeil sur votre stockage cloud est important si vous ne voulez pas que la perte de donnees vous prenne par surprise. La surveillance continue vous aide a reperer les ralentissements, les acces non autorises ou les limites de capacite avant qu’ils ne menent a de plus gros problemes.
Base de donnees
Votre base de donnees fait fonctionner presque tout en coulisses. La surveiller signifie suivre la vitesse des requetes, le temps de disponibilite et les erreurs potentielles. Vous vous protegez contre des problemes comme les pics de consommation memoire ou les goulots d’etranglement de ressources qui peuvent causer des pannes.
Performance des applications
La surveillance de la performance des applications vous donne un controle en direct de la facon dont vos applications se comportent sous pression. Vous pouvez l’utiliser pour suivre les experiences utilisateur, detecter les ralentissements et reperer les problemes backend tot. Cela vous aide aussi a relier les baisses de performance directement aux objectifs de l’entreprise, afin de prioriser les corrections qui comptent le plus.
Securite
La surveillance de la securite vous alerte sur toute activite inhabituelle qui pourrait signifier des failles de securite ou des vulnerabilites. Avec une detection intelligente des anomalies, vous attrapez les risques avant qu’ils ne deviennent des incidents majeurs et protegez vos utilisateurs.
Couts
Sans suivre vos couts cloud, vous pourriez finir par payer pour des ressources sous-utilisees dont vous n’avez meme pas besoin. Une bonne solution de surveillance garde vos depenses alignees avec votre utilisation reelle. Cela peut vous aider a realiser des economies.
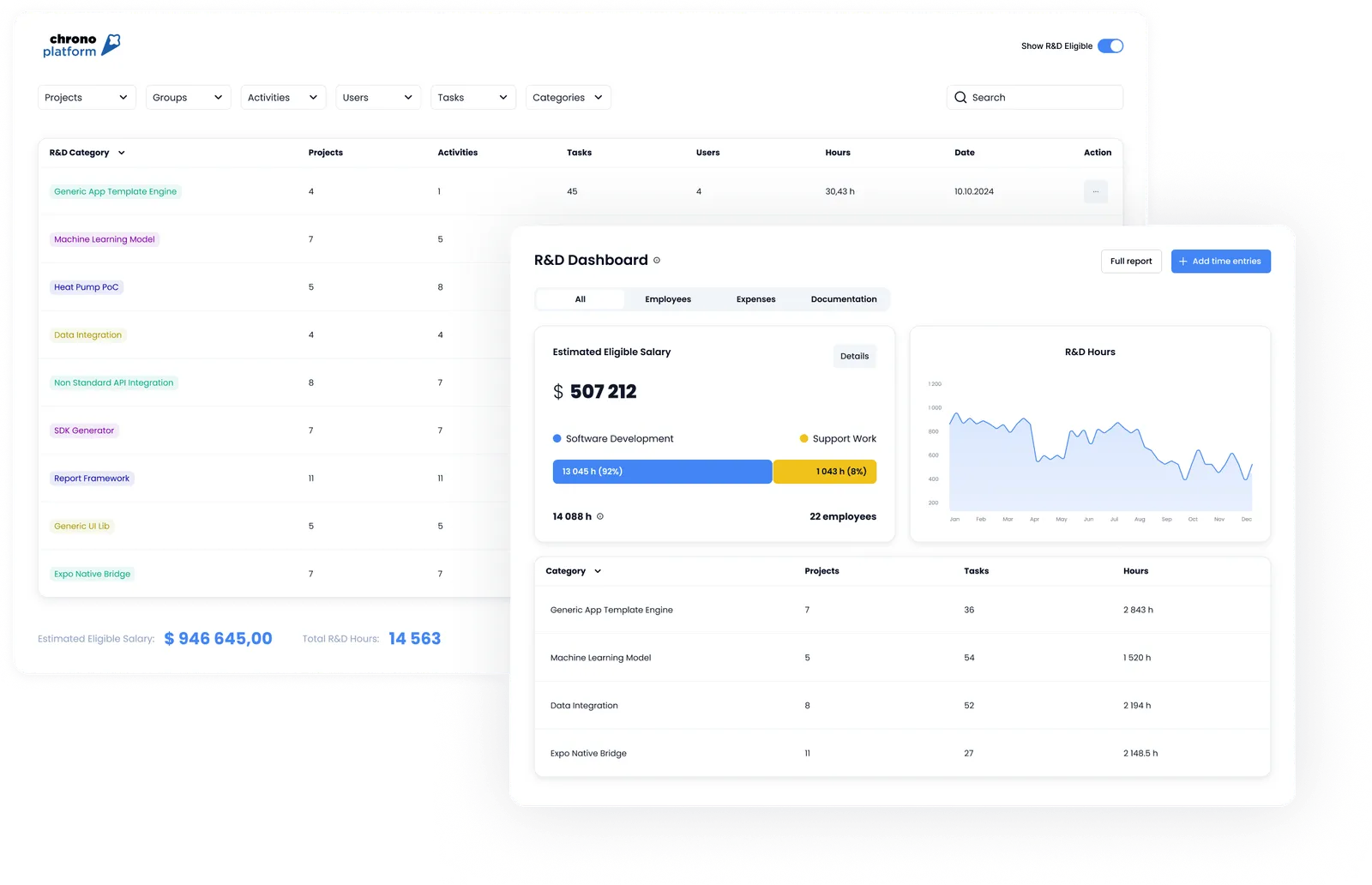
Conseil pro : Chrono Platform aide les equipes a organiser le temps d’ingenierie et les couts associes pour les initiatives R&D. Dans de nombreuses juridictions (comme le Canada, les Etats-Unis, certaines parties de l’Europe), l’infrastructure cloud utilisee pour le developpement experimental, le prototypage ou les tests est admissible comme depense R&D eligible. Ainsi, utiliser Chrono facilite l’attribution de l’utilisation cloud eligible a des programmes comme la RS&DE.
Facturation
La surveillance de la facturation lie tout ensemble. Elle vous aide a reperer les erreurs de facturation, les pics inattendus ou les deploiements inefficaces qui grugent votre budget cloud. Rester a jour vous donne un meilleur controle sur les depenses cloud et maintient vos operations financierement saines.
Pourquoi la journalisation et la surveillance sont-elles importantes dans un environnement cloud ?
La journalisation et la surveillance sont importantes dans un environnement cloud parce qu’elles vous donnent la visibilite necessaire pour garder vos systemes en bon fonctionnement, attraper les problemes tot et eviter de naviguer a l’aveugle. Dans les environnements cloud natifs distribues, l’observabilite est beaucoup plus difficile, et sans journaux ou metriques clairs, diagnostiquer les problemes devient de la pure conjecture.
Voici pourquoi la journalisation et la surveillance comptent autant :
- Reponse aux incidents : Vous pouvez reperer les problemes tot et reagir plus vite, ce qui vous aide a reduire le temps de reponse aux incidents et a eviter les temps d’arret majeurs.
- Audit : Les developpeurs obtiennent une piste claire et fiable de qui a fait quoi. Cela rend les revues internes et les audits externes beaucoup plus faciles.
- Suivi des couts : Vous pouvez surveiller l’utilisation des ressources et reperer le gaspillage, ce qui mene a une meilleure gestion des investissements cloud.
- Conformite : Les gestionnaires peuvent respecter les regles de securite et de confidentialite en montrant qu’ils protegent activement leurs systemes.
- Optimisation de la performance : La surveillance en temps reel met en evidence les services en retard pour que vous puissiez corriger les problemes avant meme que les utilisateurs ne les remarquent.
- Surveillance de la securite : Vous restez alerte face aux menaces de securite comme les connexions suspectes ou les attaques d’API. Cela peut vous aider a agir avant que les choses ne s’aggravent.
- Efficacite operationnelle : Avec des alertes automatisees, vous passez moins de temps a chercher des donnees et plus de temps a ameliorer les systemes.
- Benchmarking et ameliorations : Vous construisez des references de performance au fil du temps pour mesurer si les changements ameliorent reellement votre systeme.
Globalement, une journalisation et une surveillance robustes vous aident a reduire le temps de resolution, a reperer les problemes critiques avant qu’ils ne fassent boule de neige et a eviter les appels inutiles a 3 h du matin.
Comment fonctionne la surveillance cloud ?
La surveillance cloud fonctionne en vous donnant une visibilite en temps reel sur vos systemes cloud a travers la collecte de donnees, l’analyse et les alertes, afin que vous puissiez rapidement reperer les problemes et garder tout en bon fonctionnement. Voici comment le processus fonctionne generalement :
- S’appuie sur la telemetrie : Vous collectez des journaux, des metriques, des traces et des alertes pour construire un tableau complet de votre environnement cloud.
- Des agents ou services de collecte ingerent les donnees des ressources cloud : Ces outils extraient les informations de vos machines virtuelles, bases de donnees et applications pour suivre la sante et la performance.
- Les evenements sont agreges et visualises via des tableaux de bord (ex. Grafana, Datadog) : Vous pouvez facilement reperer les tendances, les baisses de performance et les problemes potentiels.
- La logique d’alerte envoie des notifications aux ingenieurs (via PagerDuty, Opsgenie, etc.) : Quand quelque chose ne va pas, les alertes en temps reel s’assurent que les bonnes personnes sont immediatement notifiees.
- La remediation automatisee et les runbooks aident a passer a l’echelle : Au lieu de paniquer a chaque incident, vous utilisez l’automatisation dans la surveillance cloud pour corriger rapidement les problemes courants et eviter les temps d’arret majeurs.
Services de surveillance cloud a connaitre
Si vous voulez garder une longueur d’avance sur les problemes et maintenir vos systemes en pleine forme, choisir le bon outil de surveillance cloud est indispensable. Voici quelques services cles a garder sur votre radar :
- Amazon CloudWatch : Service natif AWS avec une large integration a travers les ressources AWS.
- Google Cloud Operations Suite (anciennement Stackdriver) : Une solution complete pour la surveillance, la journalisation et le tracage Google Cloud.
- Azure Monitor : La plateforme de reference de Microsoft pour suivre la performance a travers les services Azure.
- Datadog : Une plateforme d’observabilite complete chargee de tableaux de bord personnalisables.
- New Relic : Offre une surveillance solide des applications et de l’infrastructure avec d’excellents outils d’analyse de cause fondamentale.
- Grafana et Prometheus : Une pile open source qui vous donne une observabilite flexible et puissante a travers les environnements cloud hybrides.
Conseil pro : Chrono Platform peut aider a faire remonter les tendances operationnelles et la fatigue d’alerte en utilisant les donnees de temps et de reponse aux incidents. Ainsi, vous gardez le controle sans vous sentir submerge.
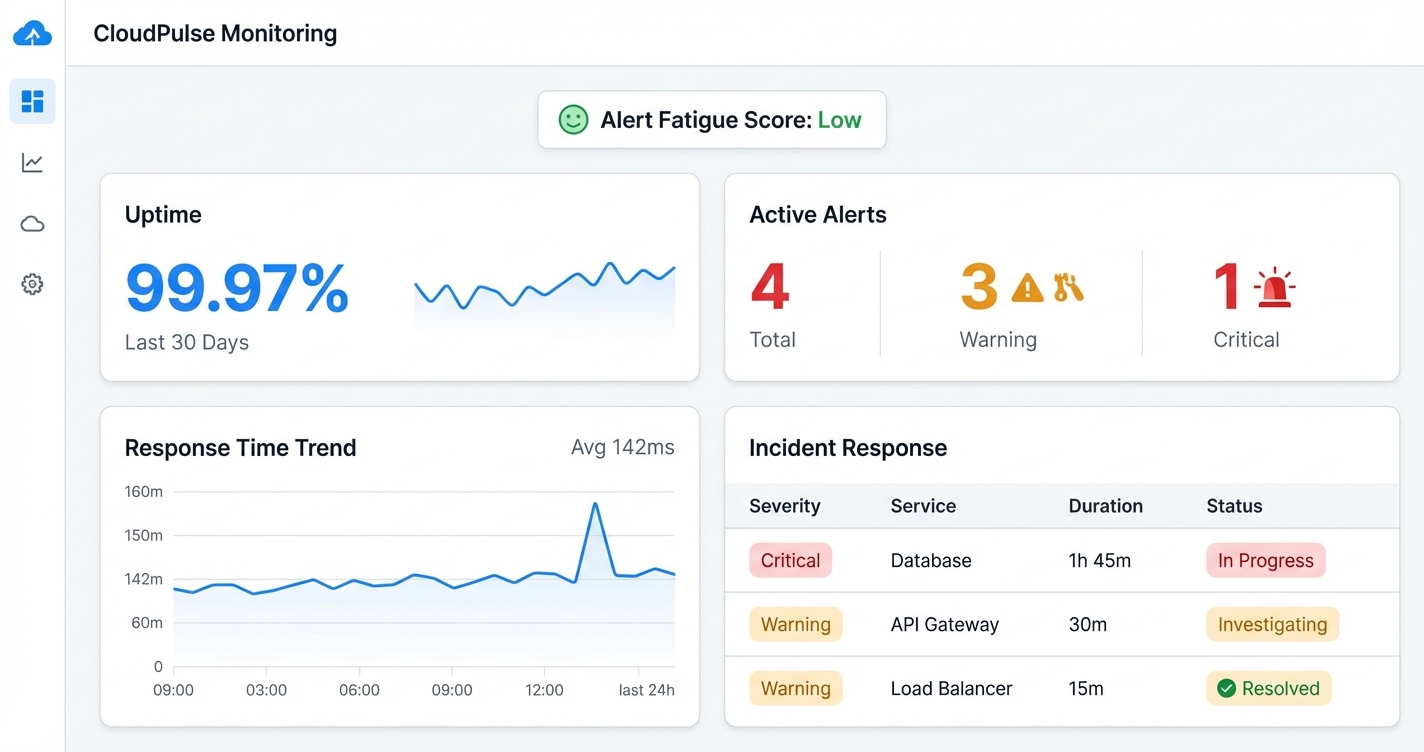
Bonnes pratiques de surveillance cloud
Quand vous voulez garder une longueur d’avance sur les problemes et maintenir vos systemes sains, suivre les bonnes pratiques est essentiel. Voici les domaines importants sur lesquels vous concentrer pour rendre votre configuration de surveillance robuste et fiable.
1. Surveillez ce qui compte / Determinez les bonnes metriques de surveillance
Vous n’avez pas besoin de tout surveiller. Concentrez vos efforts sur les systemes a haut risque, les SLA critiques et les services essentiels qui font tourner votre entreprise.
Commencez par etablir des references de performance claires pour pouvoir reellement detecter quand quelque chose ne va pas. Utilisez des SLO (Service Level Objectives) et des budgets d’erreur pour definir des seuils d’alerte intelligents au lieu de deviner.
Quand vous choisissez un outil de surveillance cloud, selectionnez-le en fonction de sa capacite a suivre vos metriques essentielles, pas juste parce qu’il a l’air bien. Garder votre focus serre economise du temps, de l’energie et beaucoup de maux de tete a long terme.
2. Reduisez la fatigue d’alerte
Vous ne pouvez pas resoudre les problemes si vous etes noye dans le bruit. Regroupez les alertes similaires pour eviter de bombarder votre equipe avec des doublons. Definissez des niveaux de severite pour que les ingenieurs sachent ce qui est critique et ce qui peut attendre.
Des regles d’escalade intelligentes ou des heures silencieuses peuvent aussi vous sauver la mise. En fait, environ 60 % des professionnels de la securite disent que la fatigue d’alerte cause des frictions internes au sein de leurs equipes.
Conseil pro : Chrono suit le temps que les ingenieurs consacrent au travail lie aux incidents. En gros, il organise les activites pour faire remonter la tension operationnelle tot, sans remplacer les outils de suivi des problemes. Cela montre qui pourrait etre surcharge avant que l’epuisement ne devienne un vrai probleme.
3. Automatisez les reponses repetitives
Vous ne voulez pas que votre equipe corrige manuellement les memes problemes encore et encore. Utilisez des scripts, des playbooks ou des outils de remediation automatique pour gerer les problemes courants automatiquement. Integrer vos pipelines CI/CD avec la surveillance signifie que vous pouvez meme annuler des changements si une defaillance est detectee.
Ca en vaut la peine. En fait, automatiser les taches pourrait economiser aux employes environ 240 heures chaque annee, tandis que les dirigeants croient que cela pourrait leur en economiser pres de 360. Moins d’intervention manuelle signifie des corrections plus rapides et des ingenieurs plus heureux.
4. Planifiez les astreintes avec humanite
Les astreintes ne doivent pas ressembler a une punition. Alternez les horaires equitablement et soyez transparent sur qui couvre quoi. Donnez toujours du temps de recuperation apres des quarts imprevus plus longs — vous ne dirigez pas une armee de robots.
Une etude McKinsey montre que 28 % des employes americains presentent des symptomes d’epuisement professionnel, les responsabilites d’astreinte etant une grande partie du probleme. La fonctionnalite de capacite a la demande de Chrono vous donne acces a des equipes dediees. Cela signifie que vous pouvez aligner les horaires avec la disponibilite reelle et la charge de travail de votre equipe. Cela ameliore la vie de tout le monde.
5. Investissez tot dans l’observabilite
Attendre que les problemes de production surviennent pour penser a l’observabilite est une recette pour le chaos. Mettez en place une journalisation, des metriques et un tracage adequats des le depart pour construire une base solide. Essayer de retrofiter l’observabilite plus tard est desordonné, couteux et stressant.
Les equipes qui priorisent l’observabilite tot tendent aussi a avancer plus vite. Environ 60 % des equipes ameliorant leurs pratiques d’observabilite rapportent un depannage plus rapide et plus precis. Prenez les devants au lieu de constamment courir apres les problemes.
6. Implementez des metriques coherentes a travers les environnements
Vous ne pouvez pas gerer ce que vous ne mesurez pas de facon coherente. L’utilisation d’outils d’observabilite unifies vous permet de standardiser les metriques et les conventions de nommage dans chaque environnement que vous operez.
Que ce soit en staging, en test ou en production, vous devriez suivre les memes regles de surveillance pour eviter les lacunes. Quelques metriques cles a suivre incluent les temps de reponse, les taux d’erreur, l’utilisation memoire, l’utilisation de la bande passante reseau, les requetes de base de donnees lentes et la performance CPU du serveur.
Assurez-vous de ne pas vous retrouver avec des tableaux de bord fragmentes ou des alertes desalignees entre differents fournisseurs cloud. Utilisez un tableau de bord unique pour rester clair et concentre. Avec 92 % des entreprises adoptant maintenant une strategie multi-cloud et 80 % s’appuyant sur une approche hybride, garder des metriques coherentes entre les plateformes n’est pas seulement intelligent mais necessaire.
7. Ameliorez continuellement votre surveillance
Vous devriez traiter votre configuration de surveillance comme un systeme vivant, pas un projet ponctuel. Faites toujours des post-mortems d’incidents pour reperer les points faibles. Suivez des metriques importantes comme le MTTR, le volume d’alertes par equipe et l’impact sur les ingenieurs pour trouver des domaines d’amelioration.
Pres de 23 % des equipes ont dit qu’elles faisaient de grands progres dans la reduction de leur MTTR, tandis que 9 % ont dit avoir fait des ameliorations majeures. Mais pres d’une equipe sur 5 a encore besoin de progres serieux, et 41 % disent qu’elles ne font que des gains lents.
Ne laissez pas votre equipe stagner ; continuez a ajuster votre systeme au fil du temps.
8. Surveillez l’experience utilisateur, pas seulement l’infrastructure
Vous ne pouvez pas pretendre que vos systemes sont sains si vos utilisateurs galèrent encore. Vous devriez combiner les metriques backend comme la disponibilite serveur avec la telemetrie frontend comme les vitesses de chargement de page, les etats d’erreur et les points de friction UX. Les verifications synthetiques sont un excellent moyen de simuler le comportement reel des utilisateurs et de reperer les problemes tot.
Vous devriez aussi faire correspondre les KPI d’affaires, comme les taux de succes de paiement ou les flux d’inscription, a vos indicateurs de sante systeme. Une bonne surveillance signifie regarder l’image complete, pas seulement le backend.
9. Regroupez l’infrastructure par service/application
C’est facile de se perdre si vous surveillez chaque machine virtuelle ou conteneur separement. Au lieu de cela, regroupez votre infrastructure par les services ou applications qu’elle supporte. Ainsi, quand quelque chose casse, vous savez exactement ou chercher.
Regrouper par service rend aussi vos alertes plus intelligentes et votre analyse de cause fondamentale plus rapide. De plus, cela vous aide a evoluer sans creer un « spaghetti d’alertes » que personne ne peut demeler. Garder les choses orientees service facilite simplement votre vie (et celle de votre equipe).
10. Formez votre equipe a ces bonnes pratiques
Vous ne pouvez pas attendre l’excellence en surveillance si vous ne formez pas correctement votre equipe. Encouragez la collaboration interequipes pour que tout le monde parle le meme langage de surveillance. Donnez a votre equipe acces a de vraies ressources, pas juste des exercices du genre « lisez la doc ».
Selon une etude du Harvard Business Review, 75 % des equipes transfonctionnelles sont dysfonctionnelles. Vous pouvez battre cette statistique en vous assurant que votre equipe connait le playbook, communique clairement et continue de progresser ensemble.
Defis de la surveillance cloud
Meme avec d’excellents outils, la surveillance cloud n’est pas aussi simple qu’il y parait. A mesure que vos systemes grandissent, les obstacles a surmonter grandissent aussi. Voici certains des plus grands defis auxquels vous devriez vous attendre :
- Complexite croissante dans les environnements multi-cloud : Vous devez jongler avec differentes API, tableaux de bord et standards selon vos fournisseurs cloud. Cela rend plus difficile de tout garder aligne.
- Surcharge de donnees avec trop de metriques : Vous pouvez suivre des centaines de metriques, mais determiner lesquelles comptent vraiment sans noyer votre equipe dans le bruit est difficile.
- Gestion des couts a travers differents services : Les outils de surveillance ne sont pas gratuits, et si vous n’etes pas prudent, les couts peuvent grimper rapidement quand vous suivez des ressources a travers plusieurs regions et services.
- Fatigue d’alerte et faux positifs : Si vous etes bombarde d’alertes constantes (beaucoup d’entre elles fausses), vous finirez par les ignorer, ce qui risque de manquer les vrais problemes.
- Manque de competences dans les outils de surveillance : Rester a jour avec le fonctionnement des differentes plateformes et former votre equipe a bien les utiliser est une bataille permanente.
Conclusion : Une surveillance cloud qui fonctionne aussi pour les humains
Votre cloud peut tourner 24/7, mais vos equipes ne devraient pas avoir a le faire. Une surveillance evoluable signifie acheter les bons outils et construire une culture qui valorise l’equilibre, la clarte et l’automatisation intelligente.
Quand vous combinez une pile d’observabilite robuste avec des plateformes comme Chrono Platform qui font remonter de vraies perspectives, vous preparez votre equipe ops a s’epanouir, pas juste a survivre. Vous creez un systeme ou les alertes ont du sens, les temps d’arret diminuent et l’epuisement reste faible.
FAQ
Quels sont les trois principaux domaines evalues par la surveillance cloud ?
La surveillance cloud evalue trois domaines principaux : la performance, la disponibilite et la securite/conformite. Vous suivez la latence, le debit et la vitesse de reponse de vos systemes pour mesurer la performance. Pour la disponibilite, vous surveillez le temps de fonctionnement et les taux d’erreur, et pour la securite et la conformite, vous cherchez les acces non autorises et les anomalies qui pourraient signaler des risques.
Qu’est-ce que la surveillance multi-cloud ?
La surveillance multi-cloud signifie que vous surveillez plusieurs fournisseurs cloud comme AWS et GCP en meme temps. Vous avez besoin d’outils capables de normaliser et centraliser les donnees de differentes sources pour obtenir une vue claire et unifiee.
Qu’est-ce qu’un logiciel de surveillance d’infrastructure cloud ?
Un logiciel de surveillance d’infrastructure cloud vous aide a suivre la sante et la performance de vos serveurs, VM, conteneurs, bases de donnees et plus encore. Des outils comme Datadog, New Relic et Prometheus vous donnent la visibilite dont vous avez besoin pour rester en avance sur les problemes.
Qu’est-ce que la surveillance de cloud hybride ?
La surveillance de cloud hybride couvre les environnements qui utilisent a la fois des systemes sur site et des clouds publics ou prives. Cela peut devenir complique parce que vous avez affaire a des frontieres de reseau, des systemes d’identite et des outils fragmentes qui ne s’entendent pas toujours bien.
Quelles sont les trois parties de la surveillance cloud ?
Quand vous decomposez, la surveillance cloud se concentre sur trois choses : la performance, la securite et la conformite. Chacune compte si vous voulez des operations cloud fiables et sures.
Qu’est-ce qu’un outil de surveillance cloud ?
Un outil de surveillance cloud est un logiciel qui surveille la disponibilite, la performance et la securite de vos configurations cloud. C’est votre systeme d’alerte precoce pour reperer les problemes avant qu’ils ne nuisent a votre entreprise.
Quelle est la difference entre la surveillance cloud et la gestion cloud ?
La surveillance cloud consiste a observer et reperer les problemes au moment ou ils surviennent. La gestion cloud va plus loin en prenant des mesures pour corriger, faire evoluer ou optimiser votre environnement.
